用 Python 对新冠病毒做数据分析,我们得出哪些结论?
Posted
一种最初在中国城市武汉被发现的病毒,现在已经传播到世界上十几个国家,引发了前所未有的健康和经济危机。
世界卫生组织(简称世卫组织)宣布武汉冠状病毒爆发为「国际关注的公共卫生突发事件」。

在本文中,我们将简要回顾当前的危机,然后深入研究 Kaggle 的「Novel Corona Virus 2019 Dataset」。我创建了一个 GitHub repo,以供大家发表自己的见解。
什么是冠状病毒?
据世卫组织称,冠状病毒(CoV)是一个病毒大家族,它们引起的疾病很多,包括普通感冒和更严重的疾病,如中东呼吸综合征(MERS-CoV)和严重急性呼吸综合征(SARS-CoV)。
新型冠状病毒(nCoV)是一种新的病毒株,此前尚未被人类发现。最近爆发的病毒被称为 2019-nCoV 或武汉冠状病毒。
我们面临的危机
此前,据《纽约时报》的一篇报道,「确诊感染人数上升至 37198 人」,「中国死亡人数上升至 811 人,超过了非典疫情造成的死亡人数」。
中国有 16 个城市,超过 5000 万人口,正处于封锁状态。全球各地的航空公司都取消了往返中国的航班。一些国家正通过特别航班疏散本国公民,并进一步对他们实施严格的隔离。
更糟糕的是,中国股市暴跌,全球股市受到了影响。一些分析人士预测,疫情对全球经济构成的威胁,有可能引发深远的政治后果。
数据集简介
约翰霍普金斯大学收集了「Novel Corona Virus 2019 Dataset」,并将该数据集发表在 Kaggle 上。该小组从世界卫生组织、当地疾控中心和媒体等不同渠道收集了这些数据。他们还创建了一个实时仪表盘来监控病毒的传播
免责声明:请注意,数据集没有更新,因此下面记录的结果可能不是当前现状的真实反映。
导入库并加载数据
理解数据集
让我们首先对数据集有一个基本的了解,并在必要时执行数据清洗操作。
输出:(770,8)。数据集中有 8 列共 770 个观测值。
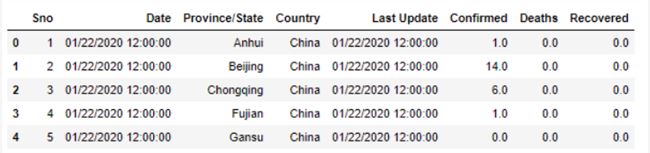
列的名称显而易见。第一列「Sno」看起来像行号,不向分析添加任何值。第五列「Last Update」显示的值与「Date」列相同,但少数情况下,这些数字稍后会更新。在继续之前,我们先删除这两列。
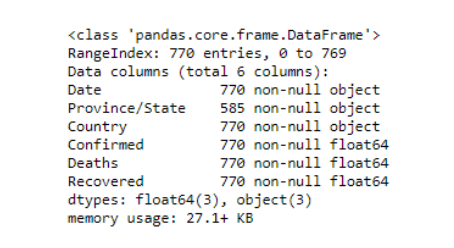
除「Province/State」外,所有列都没有空值。进一步分析显示,英国、法国和印度等国的省份名称都不见了。在这种情况下,我们不能假设或填充任何主列表中缺少的值。让我们转到数字列。
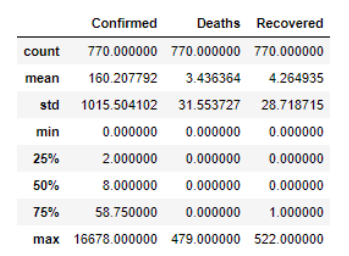
describe() 方法返回数据帧中数值列的一般统计信息。
这个输出可以得到的一个直接结论是,数据已经累积报告,即任何一天报告的病例数包括先前报告的病例。死亡的最大值是 479,这与几天前媒体的报道(在这一数据公布时)是一致的。

duplicated() 方法返回一个布尔序列,然后将其用作原始数据帧的掩码。结果显示没有两个记录具有相同的国家、州和日期。因此我们可以得出结论,数据集中的所有观测值都是唯一的。

数据显示,该病毒已经传播到亚洲、欧洲和美洲的 32 个国家。为了进行分析,我们可以合并「China」和「Mainland China」的数据。
在开始之前,让我们检查一下 [Date] 栏中的日期。

数据似乎每天都在不同的时间更新。我们可以从时间戳中提取日期并将其用于进一步的分析。这将有助于我们保持日期一致。
让我们了解一下疫情对每个国家的影响。
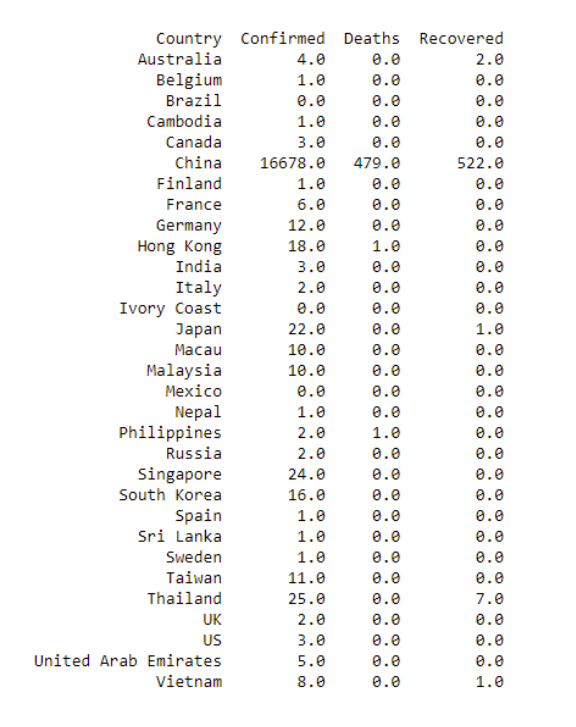
由于数据是累积的,所以我们需要使用 groupby() 和 max() 函数,以获得每个国家报告的最大数目。如果我们使用 sum(),则会导致重复计算。
数据证实,迄今为止,中国报告的病例最多,481 例死亡病例几乎全部来自中国。但另一方面,中国也有 522 人康复,其次是泰国,有 7 人康复。
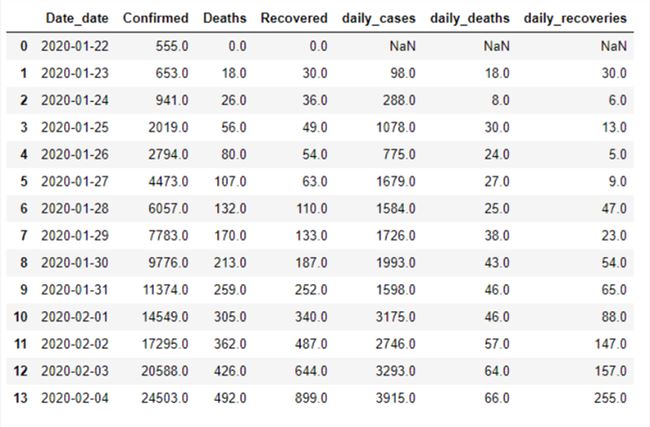
我们已经完成了数据预处理步骤,接下来让我们继续进行数据可视化,以寻找新的趋势和模式。
来源:雷锋网
此文章 短链接: http://dlj.bz/DpPic4